单源最短路
给出一个图 ,在图中选一个起点
,在图中选一个起点 ,我们要求出从起点到图上各点的最短路径,这就是单源最短路问题 (Single Source Shortest Path, SSSP)。
,我们要求出从起点到图上各点的最短路径,这就是单源最短路问题 (Single Source Shortest Path, SSSP)。
问题分析
无环性
- 最短路是NPC问题,但当保证了图中不存在负环时,化为P问题。
考虑如果有负环,就可以一直在负环上走,永远也不会到达最短。 - 最短路是指从起点到终点的路径,可能有多条,也可能不存在(起点和终点不联通?在起点到终点的路径上可能出现负环?)
- 最长路可以用最短路解决。
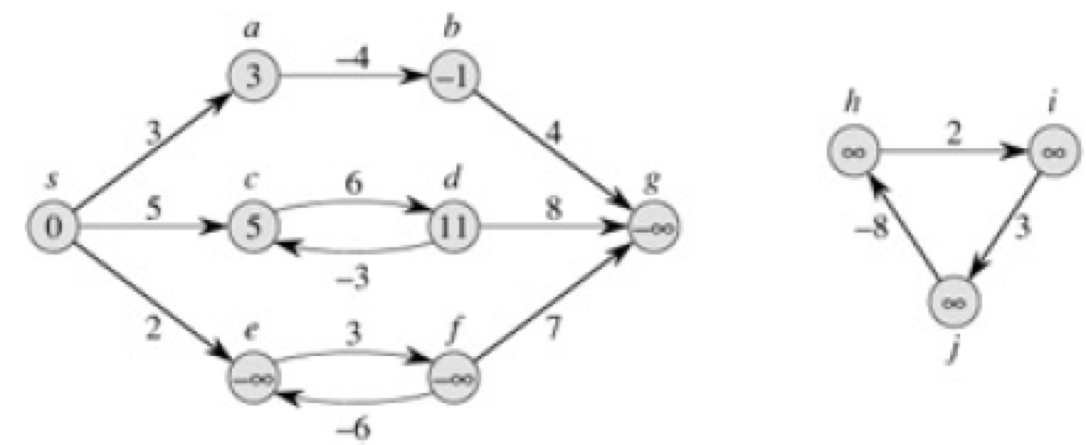
边权取负值,注意不可以有正环。 - 最短路不可能有环。
如果有正环,这个正环的一半完全可以不走。
如果有负环,可以不停在负环上走,永远取不到最短路。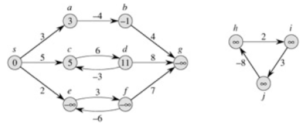
最短路没有环
传递的最优性
若最短路 经过中间点
经过中间点 ,则
,则 和
和 的路径分别是
的路径分别是 到和到
到和到 的最短路。
的最短路。
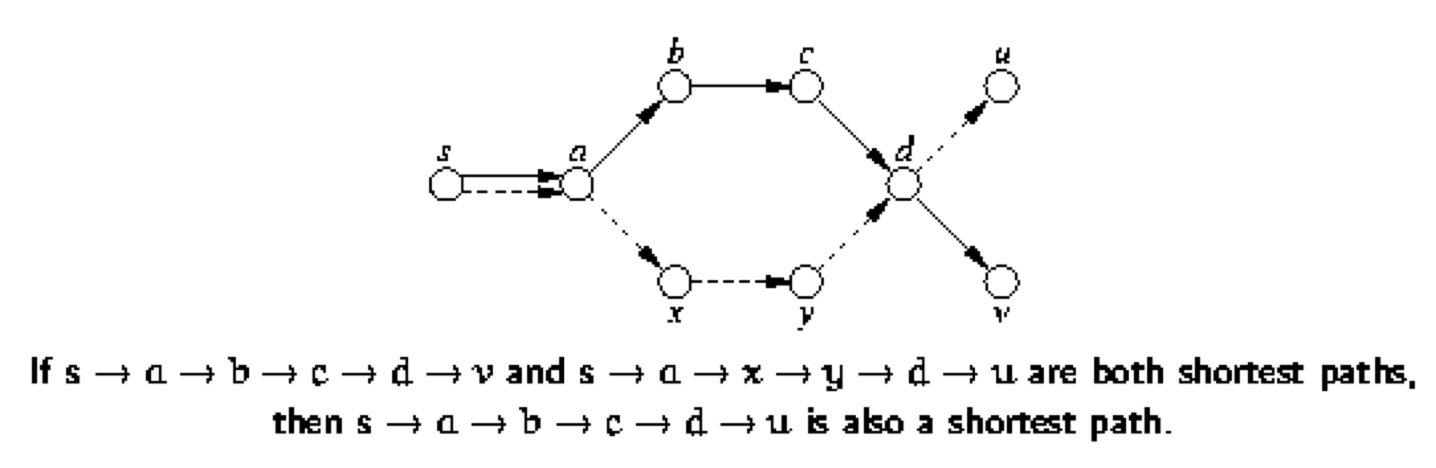
这是最短路最重要的性质,也是各种主流最短路算法的中心思想。
我们以下面图为例来进行解说,假设0号点为指定的起点:
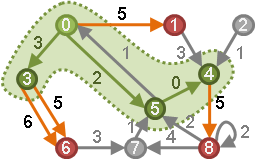
图中绿色的部分是我们目前已经“确认”了的区域,绿色的边就是我们找出的最短路,其他颜色的点都是我们没有找出最短路的点,我们可以发现在已确认区域内部,上面的传递性当然是成立的。
再考虑图中红色的部分,这些都是从绿色区域可以直接到达的,也就意味着一定存在一条路径,前面若干条边都是绿色的,最后一条边是红色的,而且这条路径是从起点到红色的店的最短路(当然,在确定了这条最短路之后,这个红色的点和红色的边会被设定为绿色,这个点的其他入边会变为灰色)。
这种性质提示我们可以记录从起点到已经确认的点的最短路,也就是说利用动态规划的思想。
同时我们也可以提出下面的两种贪心想法:
- 如果一个红色的点的所有入边都已经变红,只要选取里面最短的那个红边纳入最短路,就可以得到这个点对应的最短路(最短连最短一定最短)。
- 如果没有任何一个红点的所有入边都变红,那么我们可以试算每个红点经由红边得到的最短路,挑选里面最短的那个纳入绿色区域(因为这个时候这个点已经不可能取到更短的路径了)。
根据最优性的传递性,这两种贪心的想法都是合理的。主流的最短路算法都是基于动态规划思想和贪心思想的。
最短路树/最短路DAG
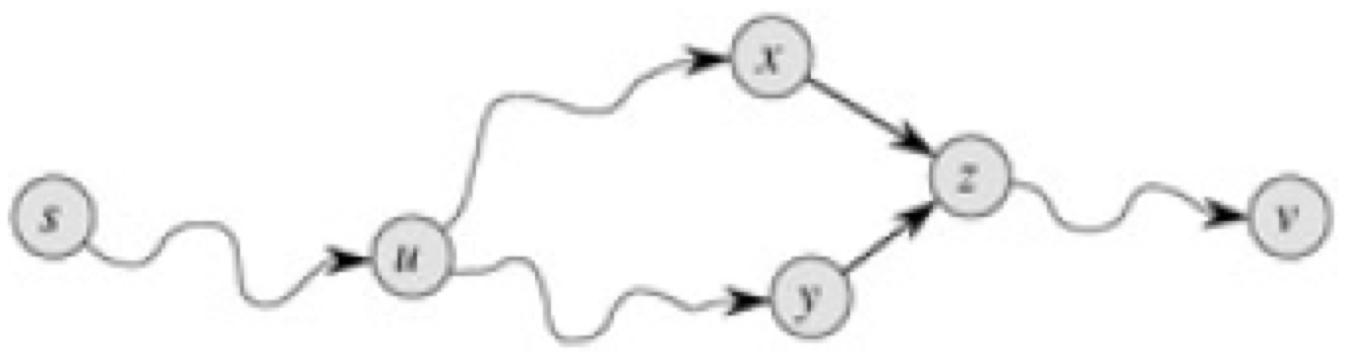
前面提到了最短路的无环性和传递性,假设每个点对应的最短路的解是唯一的,我们可以轻松发现,把所有点的最短路对应边在图上染出来,同所有的点一起正好形成一棵树。
如果考虑多解,就会形成一个DAG。
算法
下面将会介绍几种主流的单源最短路算法及其实现,依然以此图举例:
在开始之前,我们要介绍一个术语“松弛(Relax)”,松弛操作可以表示为:
|
1 2 3 4 |
if(dis[v] > dis[u] + len[i]) { dis[v] = dis[u] + len[i]; prv[v] = u; } |
其中dis是从起点到某个点的距离,len是边的长度,u是一个绿色点,v是一个红色点,prv表示某个点在最短路上的前趋。也就是说松弛操作实际上就是试算红色点最短路的过程。
Bellman-Ford
Bellman-Ford 算法可以概括为:不停进行迭代,每次迭代尝试松弛所有边,迭代最多进行 次(
次( 是图的点数),如果一次迭代中没有进行任何成功的松弛,算法可以立即终止,算法复杂度为
是图的点数),如果一次迭代中没有进行任何成功的松弛,算法可以立即终止,算法复杂度为 (E是图的边数)。实现如下:
(E是图的边数)。实现如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// n : 点数 // m : 边数 // dis[x] : 从起点到x的最短路长度 // from[i] : i号边从哪个点开始 // ed[i] : i号边到哪个点结束 // len[i] : i号边长度 // prv[x] : x的最短路前趋 //一开始,所有点的dis都设为无穷大,起点设为0 for(int i = 1;i <= n;i++){ dis[i] = INF; } dis[s] = 0; //最多进行n-1次迭代 for(int i = 1;i <= n-1; i++){ bool relaxed = false; for(int j = 1;j <= m; j++){ //对每条边都尝试一次松弛操作 int u = from[j], v = ed[j]; if(dis[v] > dis[u] + len[j]){ dis[v] = dis[u] + len[j]; prv[v] = u; relaxed = true; } } //如果没有一次成功的松弛,算法可以提前退出 if(!relaxed) break; } |
为什么这种算法是合理的呢?联想我们提到的最短路的性质:
- 所有的最短路形成树,根据树的性质,N个点的树有N-1条边。
- 基于两个贪心的想法,如果我们每一轮迭代都松弛每个边,每一轮都可以确定一个红点成为旅店,一定至少往最短路树中增加一条边。
- 这样,我们至多经过N-1次迭代可以得到最短路。
如果图里有负环,会发生什么呢?我们知道经过N-1次迭代就可以确认所有点的最短路了,也就是说第N次迭代将会没有成功的松弛。但是如果有负环,松弛过程将不断尝试在负环中回环,也就是说第N次迭代中将会出现成功松弛。我们可以利用这个特性来判断图中是否有负环。
SPFA
Shortest Path Faster Algorithm实际上是Bellman-Ford的队列实现。我们注意到在上面的迭代实现中,我们每一次都访问了许多绿色边和灰色边,而这些边的松弛操作实际上都是没有用的,如果我们使用队列实现,每一次只松弛红色边,算法的效率就会有所提高。SPFA的代码实现如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
//n:点数 //m:边数 //dis[x]:起点到x的最短路距离 //inque[x]:x点是否在队列里 //prv[x]:x点的最短路前趋 //head[],nxt[],from[],ed[]:参见邻接表 queue<int> que; //初始化dis数组和inque数组 for(int i = 1;i <= n;i++){ dis[i] = INF; inque[i] = false; } dis[s] = 0; que.push(s); inque[s] = true; while(!que.empty()){ int u = que.front(); que.pop(); inque[u] = false; for(int i = head[u];i;i = nxt[i]){ if(dis[v] > dis[u] + len[i]){ dis[v] = dis[u] + len[i]; prv[i] = u; if(!inque[v]){ que.push(v); inque[v] = true; } } } } |
SPFA的复杂度与Bellman-Ford相同,都是,然而在实际应用中,SPFA很少会达到这么高时间,在一些情况中,SPFA的效率甚至比Dijkstra高。
Dijkstra
Dijkstra算法适用于所有的边权都为正的图,算法的语言表述如下:
- 初始化访问标记数组vis[]为全false,vis[x]表示x是否被访问过
- 初始化距离数组dis[]为全INF,dis[起点s]为0,dis[x]表示起点到s的距离
- 执行n次下述过程(n为图的点数):
- 在所有vis为false的点中挑一个对应的dis值最小的出来(如果有多个就随便选一个),令其为u
- 令vis[u]=true
- 对于所有u出发的边,进行一次松弛操作
可以发现,在Dijkstra算法中,一个点只要被访问,就会变成绿色点,也就是这个点对应的最短路被确认。联想我们上面提到过的传递性质里面的贪心思想,不难说明这种方法的合理性。假设一个点t在被访问的时候并没有取到最短路,那么必然存在另外一条更短路径能够到达t点,因为我们每一次挑选dis最小的点访问,那么这条更短路径中与t邻接的那个点必然会被先行访问,所以不存在这种不合理的情况。
那么,为什么Dijkstra不适用于带有负权边也可以得到解释,如果没有负权边,最短路径上面的dis值可以保证单调,然而引入负权边之后这种单调性就消失了,我们之前的贪心策略也就不合理了。
Dijkstra的实现难点主要在“挑选已访问点中dis最小的那个”这一步上,这里是Dijkstra性能的瓶颈,这一步通常使用堆结构来实现。C++ STL中自带的优先队列由于无法进行堆内值的变更操作,所以实现出来的复杂度并不稳定(因为部分点会重复入队),而且可能需要使用仿函数技术进行运算符重载,一个如此实现的例子如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
//n:点数 //m:边数 //dis[x]:起点到x的最短路距离 //vis[x]:x点是否在访问过 //prv[x]:x点的最短路前趋 //head[],nxt[],from[],ed[]:参见邻接表 struct Node{ int id,dis; bool operator () (const Node &a, const Node &b){ return a.dis < b.dis; } }; priority_queue<Node, vector<Node>, greater<Node> > que; for(int i = 1;i <= n;i++){ dis[i] = INF; vis[i] = false; } dis[s] = 0; que.push(s); while(!que.empty()){ int u = que.top().id; que.pop(); vis[u] = true; for(int i = head[u];i;i = nxt[i]){ int v = ed[i]; if(!vis[v] && dis[v] > dis[u] + len[i]){ dis[v] = dis[u] + len[i]; prv[i] = u; que.push({v,dis[v]}); } } } |
可以发现在实现的思路上实际上与SPFA并无太大区别,其实我们也可以把SPFA中的普通队列换成优先队列,可以有一定的启发式作用。
要真正地实现Dijkstra,除了自己手写堆之外,还可以考虑使用pd_ds扩展库,p b_ds中提供了可以调整堆内值的优先队列,但是pb_ds并不一定在所有环境中提供,有一定风险。
Gabow
这是一种与前面若干种方法截然不同的最短路算法,使用Scaling Method,这不是本文在当前版本要讨论的内容。
应用
[…待更]
多源最短路
问题概述
在单源最短路的基础上,多源最短路问题要求快速求出图中任意点对之间的最短路。
算法
除了运行N次单源最短路之外,多源最短路问题还有一种实现起来异常简单的Floyd-Warshall算法,其本质是动态规划。
|
1 2 3 4 5 6 7 |
for(int k = 1;i <= n; i++){ for(int i = 1;j <= n; j++){ for(int j = 1; k <= n; k++){ dis[i][j] = min(dis[i][j],dis[i][k] + dis[k][j]); } } } |
其中dis[i][j]是邻接矩阵,如果i->j邻接,则值为边权,否则为无穷大。在实现过程中,注意三个循环的顺序为kij并非ijk,这是为了利用CPU的缓存优化,尽量不跳行读取,这种优化可以大大提高程序运行效率。
应用
[…待更]
总结
下面这张简单的思维导图大略的列出了最短路相关的部分考点。
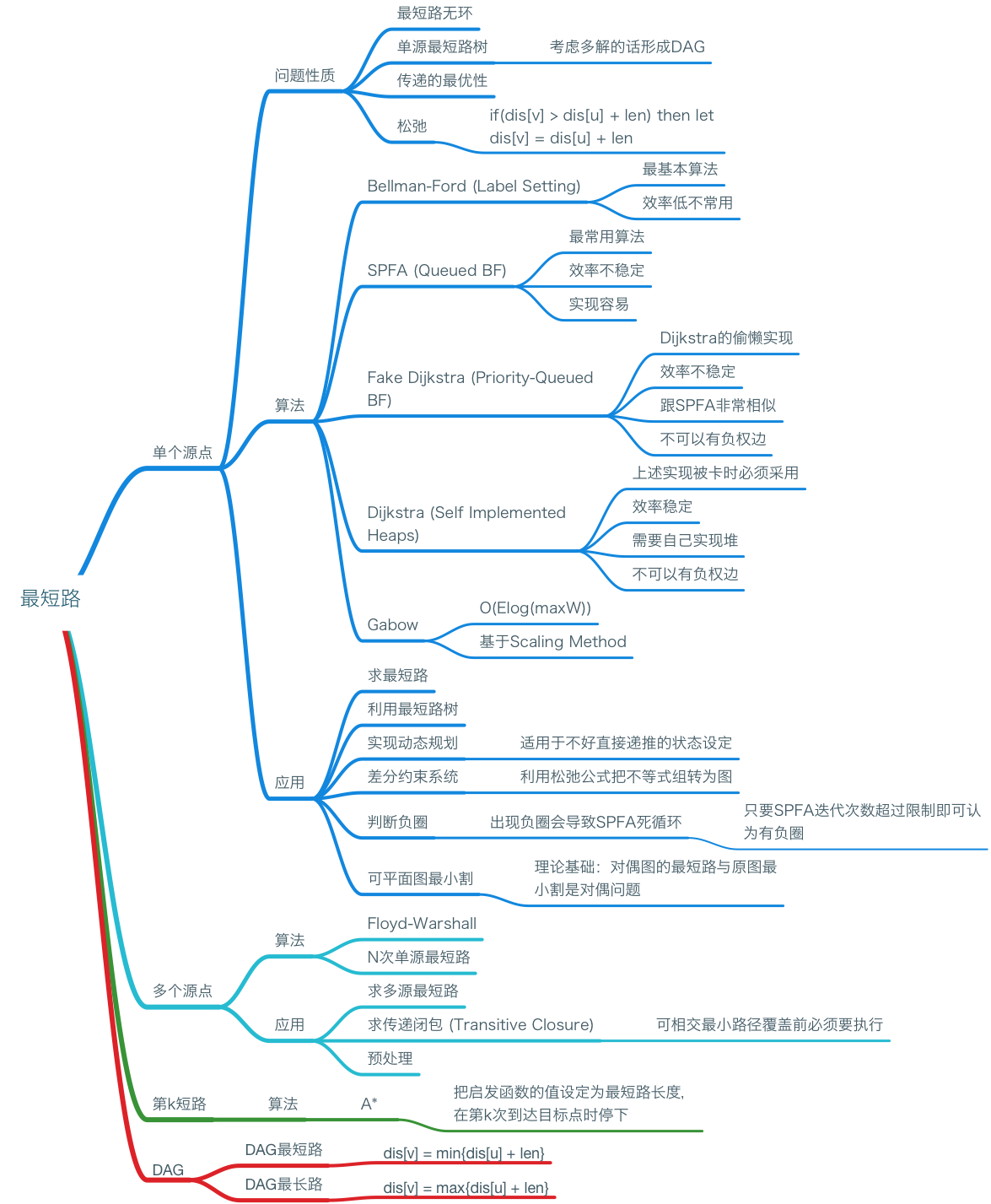 最短路相关知识的思维导图
最短路相关知识的思维导图